|
I am a fifth year Ph.D. student in the Media Lab, Dept. Electrical Engineering at The City College of New York, CUNY, advised by Professor Ying-Li Tian. My current research focuses on Video Analysis including human action recognition and self-supervised video feature learning. Prior to CUNY, I finished my Bachelor's degree from Central South University. Email / Google Scholar / Biography / LinkedIn |

|
|
News:
|
|
I am interested in computer vision, machine learning, and image processing. Most of my research is about video analysis such as human action recognition, video feature self-supervised learning, and video feature learning from noisy data. I have also worked in weakly supervised semantic segmentation and lung nodule segmentation in CT scans with Generative Adversarial Networks. |
|
Longlong Jing*, Elahe Vahdani*, Jiaxing Tan, Yingli Tian CVPR, 2021 Proposed a novel loss function named cross-modal center loss to learn modality-invariant features with minimum modality discrepancy for multi-modal data. |
|
|
Longlong Jing, Yingli Tian TPAMI, 2020 A comprehensive survey about self-supervised visual feature learning with deep ConvNets. Slides will be released very soon. |
 
|
Longlong Jing, Yucheng Chen, Ling Zhang, Mingyi He, Yingli Tian Arxiv , 2020 We proposed to jointly learn modal-invariant and view-invariant features for different modalities including image, point cloud, and mesh with heterogeneous networks for 3D data. |
 
|
Longlong Jing, Yucheng Chen, Ling Zhang, Mingyi He, Yingli Tian Arxiv , 2020 We propose a novel and effective self-supervised learning approach to jointly learn both 2D image features and 3D point cloud features by exploiting cross-modality and cross-view correspondences without using any human annotated labels. |
|
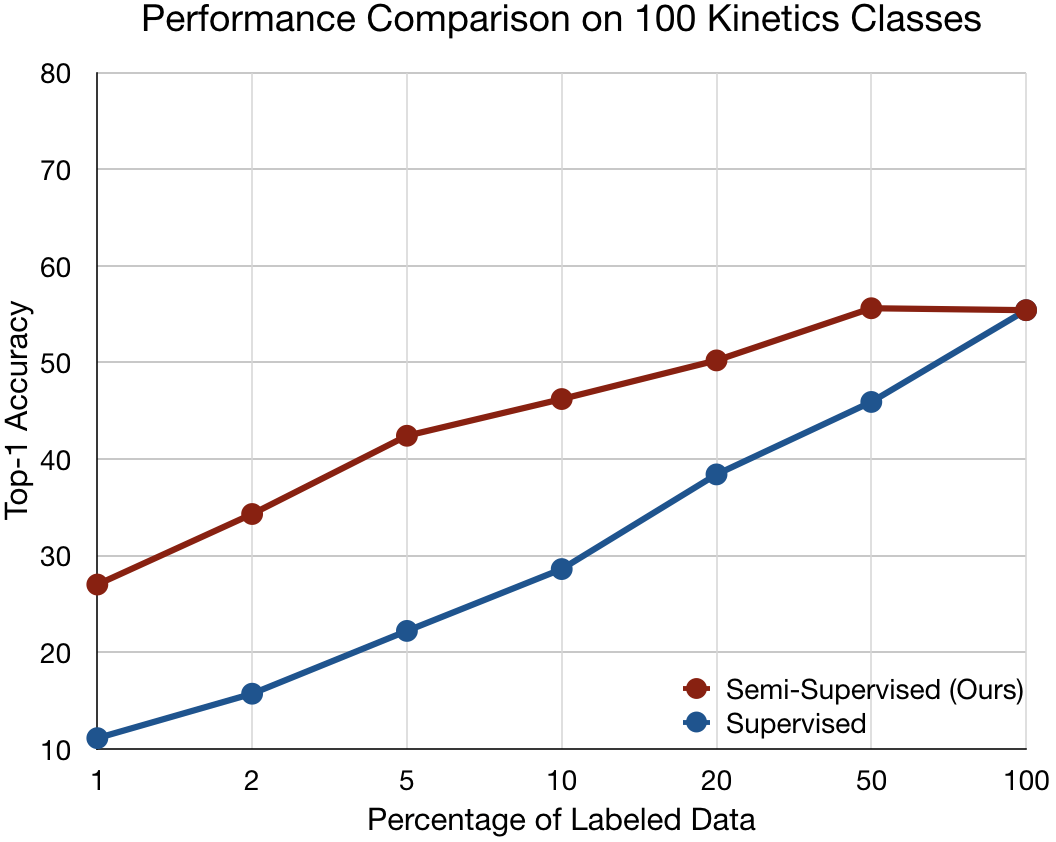
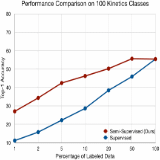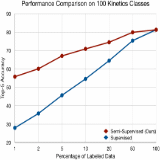
Longlong Jing, Toufiq Parag, Zhe Wu, Yingli Tian, Hongcheng Wang WACV , 2021 We propose a semi-supervised learning approach for video classification, VideoSSL, using convolutional neural networks (CNN). |
 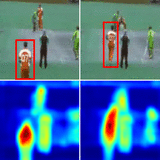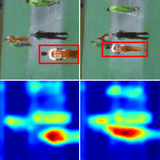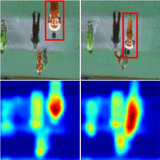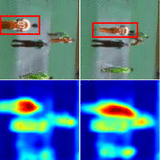
|
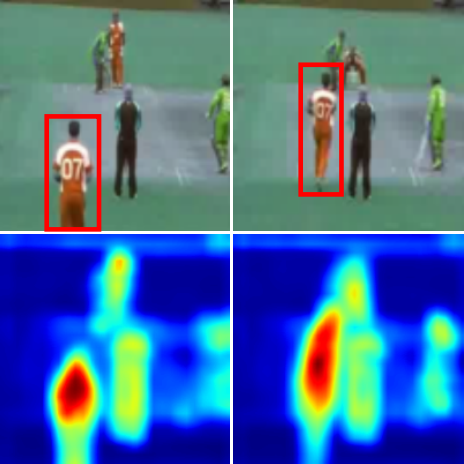
Longlong Jing, Xiaodong Yang, Jingen Liu, Yingli Tian Arxiv , 2019 We can learn spatiotemporal feature from large-scale unlabeled videos with 3D Convolutional Neural Networks. |
 
|
Yucheng Chen, Longlong Jing, Elahe Vahdani, Ling Zhang, Mingyi He, Yingli Tian CVPR AI City Workshop, 2019 PDF / Slides / Poster Our solutions to the image-based vehicle re-identification track and multi-camera vehicle tracking track on AI City Challenge 2019 (AIC2019). Our proposed framework outperforms the current state-of-the-art vehicle ReID method by 16.3% on Veri dataset. |
 
|
Longlong Jing*, Elahe Vahdani*, Yingli Tian, Matt Huenerfaut Under Review , 2020 PDF / Project Page / Dataset / We propose a 3D ConvNet based multi-stream framework to recognize American Sign Language (ASL) manual signs in real-time from RGB-D videos. |
 
|
We propose a novel recursive coarse-to-fine semantic segmentation framework based on only image-level category labels. |
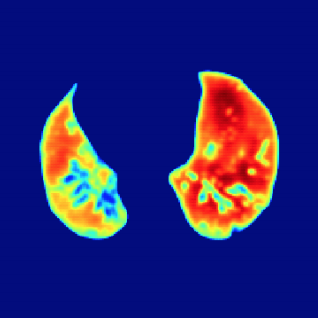 
|
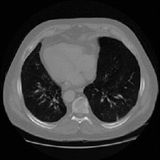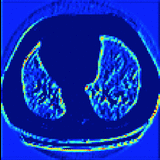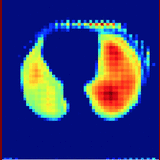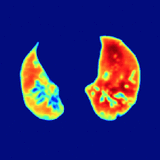
Jiaxing Tan*, Longlong Jing*, Yingli Tian, Oguz Akin, Yumei Huo CMIG, 2020 We propose a novel deep learning Generative Adversarial Network (GAN) based lung segmentation schema for CT scans by redesigning the loss function of the discriminator which leads to more accurate result. |
 
|
Longlong Jing, Xiaodong Yang, Yingli Tian JVCI, 2018 We propose an efficient and straightforward approach to capture the overall temporal dynamics from an entire video in a single process for action recognition. |
 
|
Longlong Jing, Yuancheng Ye, Xiaodong Yang, Yingli Tian ICIP, 2017 PDF / Code We propose an efficient and effective action recognition framework by combining multiple feature models from dynamic image, optical flow and raw frame, with 3D ConvNet. |